



采矿过程虽然没有创造任何实际价值,但本身维持了比特币系统的稳定性,总的来说,比特币系统中的采矿算法是成功的,没有发现任何重大漏洞。
当然,Bitcoin系统中的采矿算法也存在问题,最明显的是采矿设备专业化,这使得普通计算机用户难以参与,采矿的集中化也与“权力下放”的概念背道而驰。
因此,Bitcoin之后的许多加密货币,包括Tai Lok(Tai Lok),在弥补这一缺陷方面有所改进,Hito也实现了ASIC抵抗(耐用ASIC专用机器 ) 。 由于ASIC芯片在普通计算机中相对较高,但记录和档案管理方面没有重大缺口,通常使用的方法是记忆硬采矿谜,这增加了对记录和档案管理访问的需求。
有一次,莱特科成为比特币之后第二大货币。 其基本设计与比特币基本设计大致相同,但为了处理萨诺菲的采矿问题,进行了修改。
Lightcoin 的喷嘴以加密为基础。 加密是一种需要高度记忆性能的哈希函数,在计算机安全加密中经常使用。
Lightcoin采矿算法的基本概念
设置大数组以填充虚假随机数字。
因为我们无法预测桥函数的输出, 它看起来像一堆随机数据, 所以它叫做“假随机数字”。
例如,有一个种子节点,第一个节点是通过某种计算获得的第一个数,而每个数点是通过前一个地点的值获得的。这种填充的特征是,从这些阵列中取出数值之间有前后的依附关系。
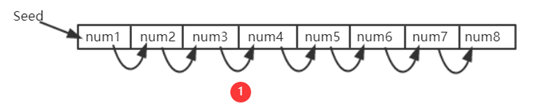
当询问对谜题的答案时,请按假随机顺序读取数组中的数组编号,每个读取位置与前一个数组相关。
例如,数据第一次从A位置读取,因为下一个读取位置B是从A位置计算的;第二次,数据从B位置读取,下一次读取位置C是从B位置计算的;
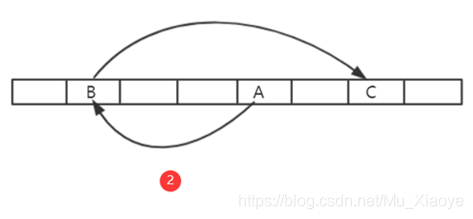
如果阵列足够大,对矿工来说,是难以记忆的,必须加以保存,以便搜索,否则,整个一系列数据不仅必须按地点计算,而且必须根据种子计算,以便能够获取相应的地点数据,而对于矿工来说,这些数据大大增加了采矿计算的复杂性。
当然,采矿者可以选择只保存部分数据,例如,只保存奇数位置数据,必要时根据先前奇数位置数据计算偶数位置,从而将内存缩小一半(计算复杂程度稍高一点,但将内存减少一半)。
核心想法:不可能仅仅计算和增加其存取记忆的机会,从而使ASIC芯片变得不友好。
这个开发协会有问题吗?
似乎相当不错,这使得ASIC采矿厂不友好,但这种方法对谜题的核查并不十分友好,因为它使谜题与解答和验证所需的记忆区一样大。 为了验证谜题,它也需要存储阵列,因此对光节点不友好(系统中的大多数节点都是光节点 ) 。
例如,对于计算机来说,1G没有压力,对于移动电话APP来说,1G占用了太多的空间。因此,实际上,Letco系统的设定尺寸只有128K。当它被释放时,它不仅想要抵抗ASIC,而且要抵抗GPU。然而,实际上,GPU矿跟随ASI芯片矿,后来又跟着ASI芯片矿。在实际应用中,Lettco的设计没有如意地奏效,也就是说,128K对于ACIC抵抗来说太小了。
设计Letcoin是好事还是坏事?
从观点来看,它没有发挥其预期的作用,但从不同的角度看,早日宣传这一设计目标实际上吸引了大量矿工,解决了莱特科“启动”问题,因此它仍然是一种更为占主导地位的编码货币。
此外,Lettco和Bitcoin之间的另一个差异是有点时间差,即2.5min和1/4的Bitcoin。 除了这些差异外,这两种货币基本相同。
Ethio的概念与Leitco的概念相同,后者都是记忆硬采矿的谜题,但并非专门设计为Leitco的概念。
以太采矿算法的基本概念
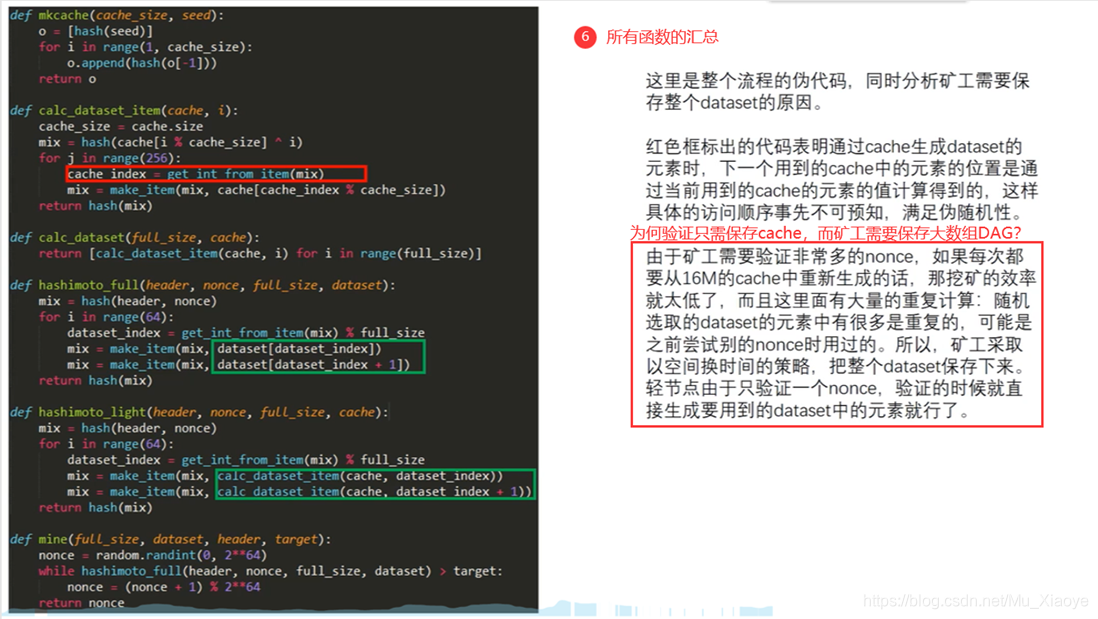
在Ethio, 设计了两个数据集, 一个大, 一个小。 较小的数据集是一个 16MB 缓存, 更大的数据集是一个 1G 数据集( DAG ) 。 在这方面, 1G 数据集是通过 16MB 数据集生成的 。
思考:为什么设计一个或两个大数据集?
为了便于验证,只需将16MB的缓存保留在光节点中即可进行验证,而矿工则需要储存1GB大小的大数据集,以便能够更快地挖掘并减少重复计算。
数据集生成
16MB的小型缓存数据生成与Lettco的类似。
第一个数字是通过种子进行的若干计算得出的,每个计算都是通过先前位置的数值得出的。
与 Lightcoin 不同 :
Letcoin: 直接读取来自数组的一些数据,按虚假随机顺序进行计算
以太:先生是一个更大的阵列。 (注:以太的这两个阵列的大小没有固定,因为鉴于计算机内存不断增长,需要定期增加。 )

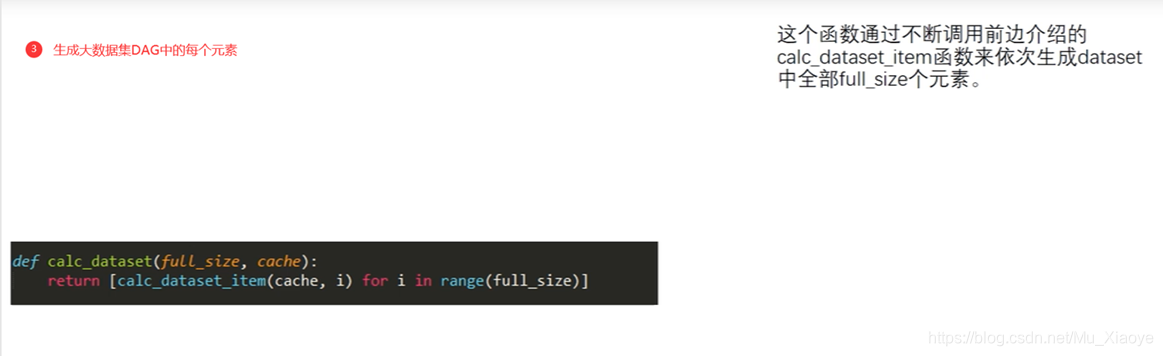
大型 DAG 生成: 大型阵列中的每个元素从小阵列中以假随机顺序读取元素, 返回 256 读数数并将其放入大阵列中 。
如果第一次读取 A 位置数据,则在更新当前Hashi 值时读取下一个位置B,然后更新Hashi 值,用于计算 C 位置元素。因此,256 重复读取导致计算数字,作为DAG的第一个元素,如果计算,则推断DAG生成每个元素的方式。
验证
光节点只保存一个小缓存,可在验证时计算。
然而,对于采矿而言,如果只保留了小的暗藏地,那么大部分的数学都花在通过缓存计算DAG上,因此,必须保留大量的DAG群,以促进更快的采矿。
解谜题
谜题的解决方案是 DAG 。 缓存不是 。
根据块块块块块块页眉及其无值计算最初的哈希,基于对初始位置A的映射,读取A位置的数和后一个位置A的数,使用这两个数字作为计算下一个位置B的基础,通过类推,读取B和B的数64,读数共计128。
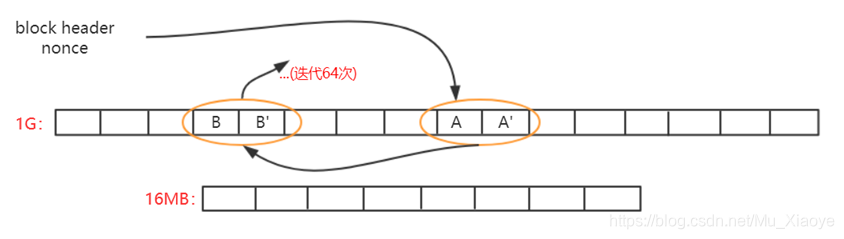
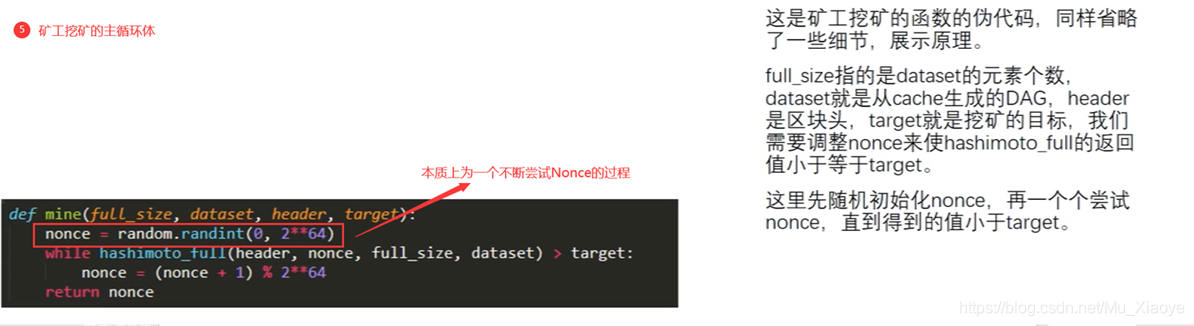
最后,与地雷困难目标阈值相比,计算出Hashi值,如果未达到,则替换Nonce,并重复上述行动,直至最终计算Hashi值以满足挑战要求或挖掘现有区块。



摘要:
目前以GPU为基础的采矿业的设计相对成功,与Ethash设计的采矿算法所需的大量记忆高度相关。
1G的大阵列比128k大8 000倍以上,甚至16MB也比128K大100倍以上,这表明对记录和档案管理的需求差距很大(两个阵列的规模在扩大)。
当然,除了采矿算法设计外,预计APIC 保留权从工作量证书(POW)改为应享权利证书(POS)还有另一个原因。
权利和利益的证据:根据有关权利投票达成共识,根据数量有限的股份(类似于股份制度)的股份数目达成共识,证明不需要采矿。
这就像一把戴摩克利斯之剑挂在一个ACIC矿工的头上。由于一个ACIC芯片的寿命周期漫长而昂贵,如果将利益转移给Taiku,这些投入的研发成本就会完全浪费。
但在现实中,以太仍然是一个Pow采矿的共识机制。 在设计开始时,以太开发者设想从Pow转向POS,以防止矿工愿意转让一枚“硬炸弹 ” 。 但迄今为止,以太继续以Pow协商一致机制为基础。
庭院使用的采矿前机制。 这里的“采矿前”不是地雷,而是用于开发开发者开发法院的资金的一部分。 法院的早期开发者现在很富有。
比特币没有遵循这种模式,所有的比特币都是从采矿中造出来的。 但早期采矿是困难的,所有中国人都有很多硬币(但没有花)
与预售前和预售前一样,预售前指的是出售储备货币用于随后的发展,类似于意外收益或人群。 目前,有许多各种加密货币,其中一部分被预售前用于获取资金。 如果当时购买,如果货币成功,也可以获得重大收益,但该货币的真正成功只是少数,风险很大。
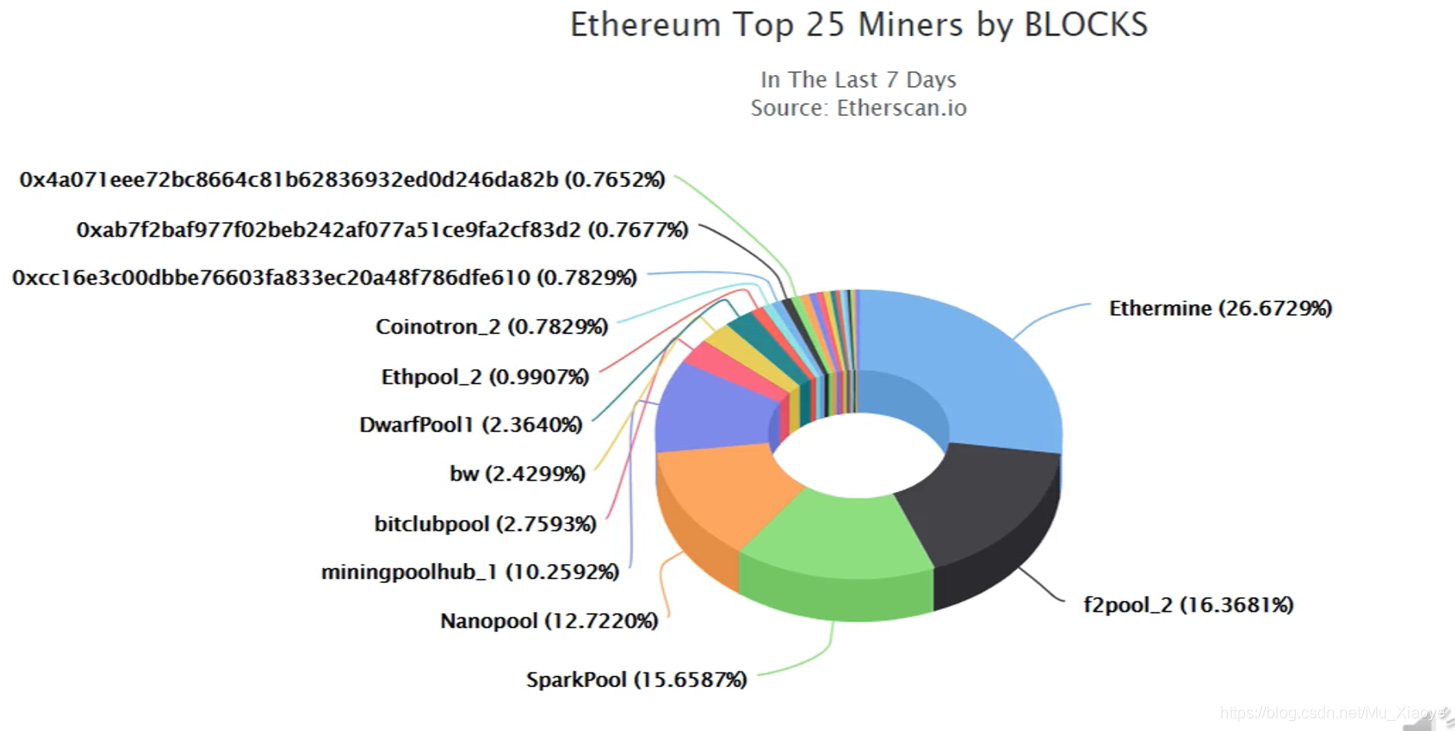
以太的以太的以太的以太的(2018年)
有大约一亿以太, 每个人的价值超过500亿美元。
馅饼的蓝色部分是由Pre-Mining(约3/4)制作的,这表明掌握技术是多么重要。 黑色部分以笔记作为奖赏,而绿色部分则以笔记记本。 绿色部分则以笔记本写成。 绿色部分则以笔记本写成。
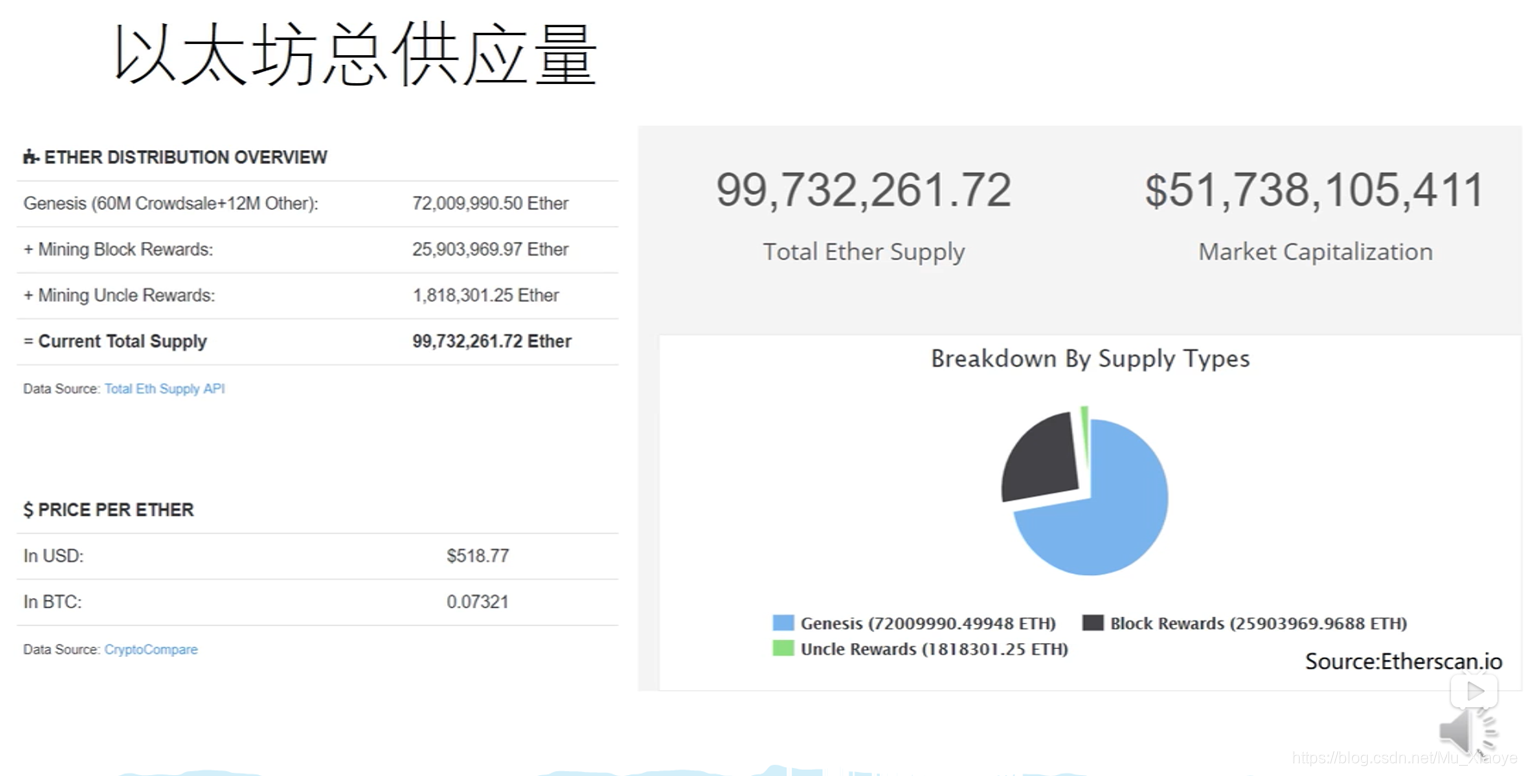
25个最大池塘的算数(2018年)
中文价格变化(至2018年)
所以,直到2017年,它才开始上升。
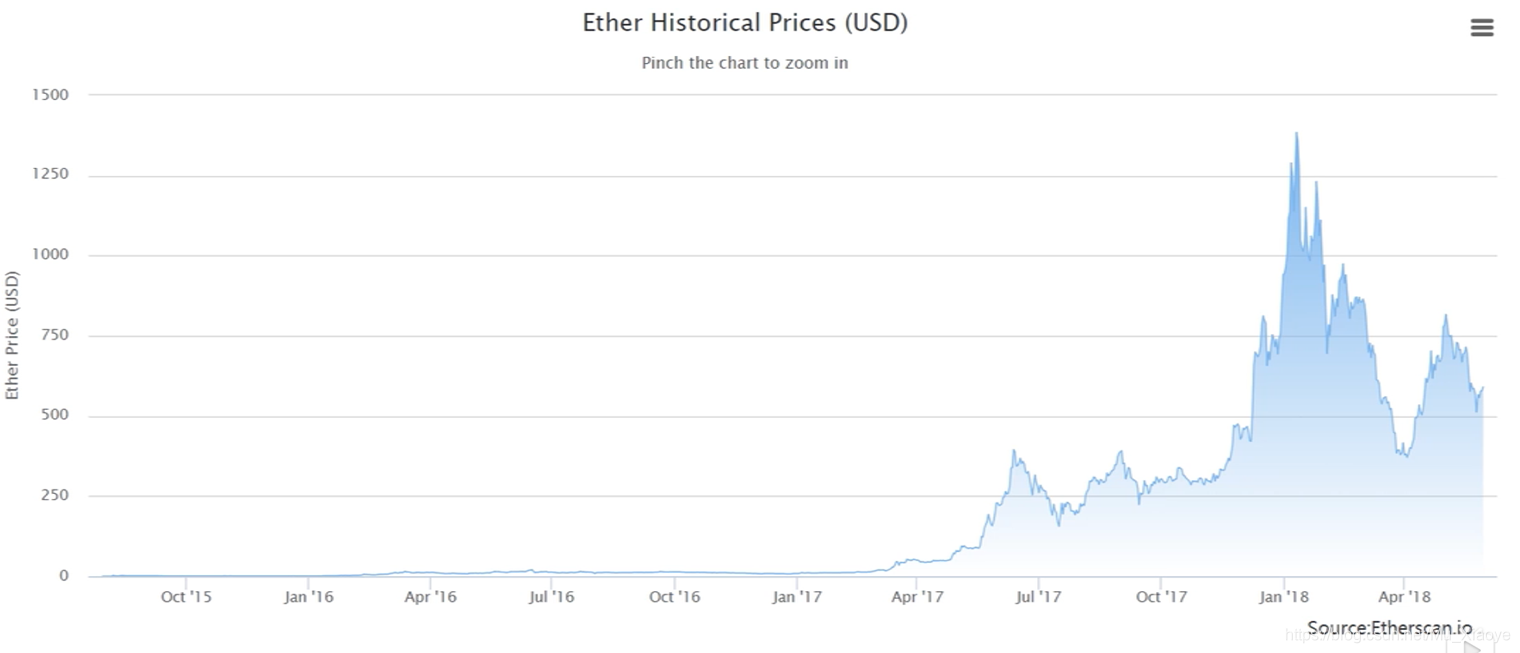
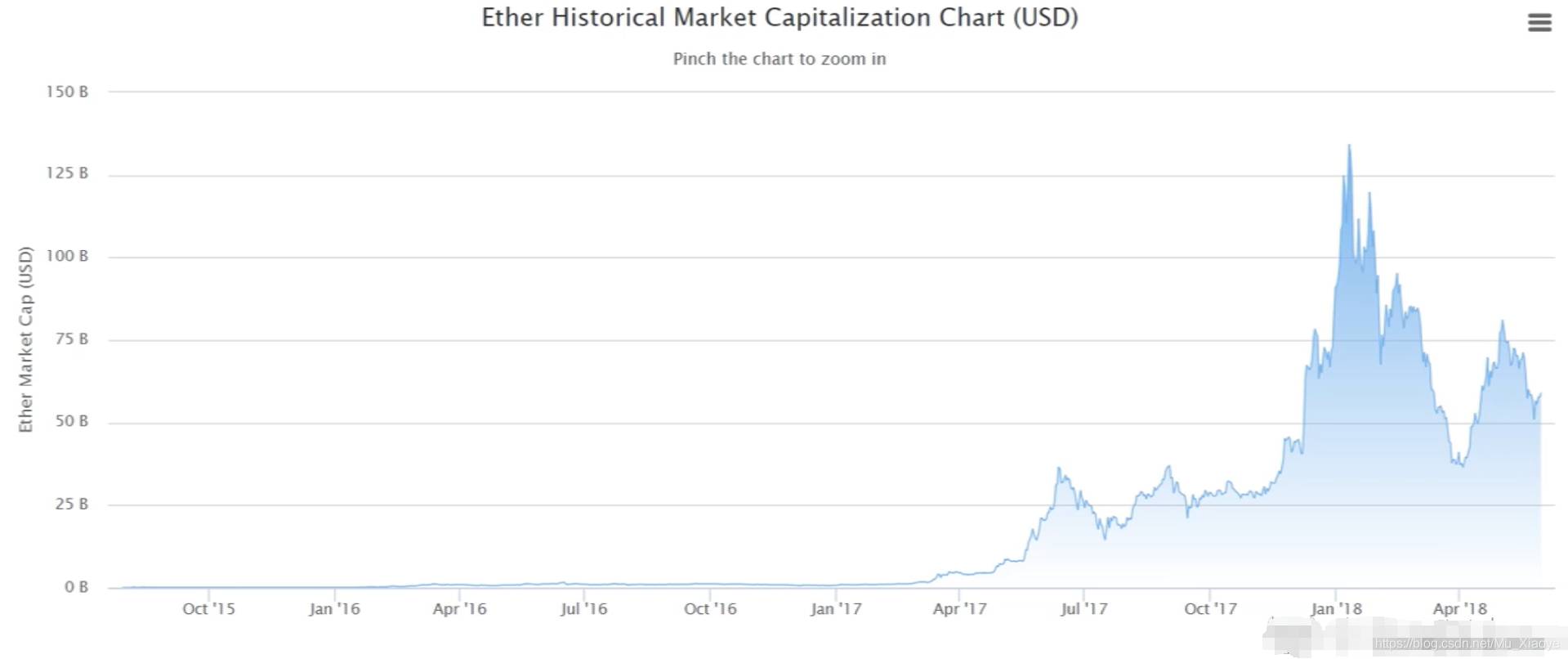
以中文计的市值变化(至2018年)
以太散列变化晚( 至2018年)
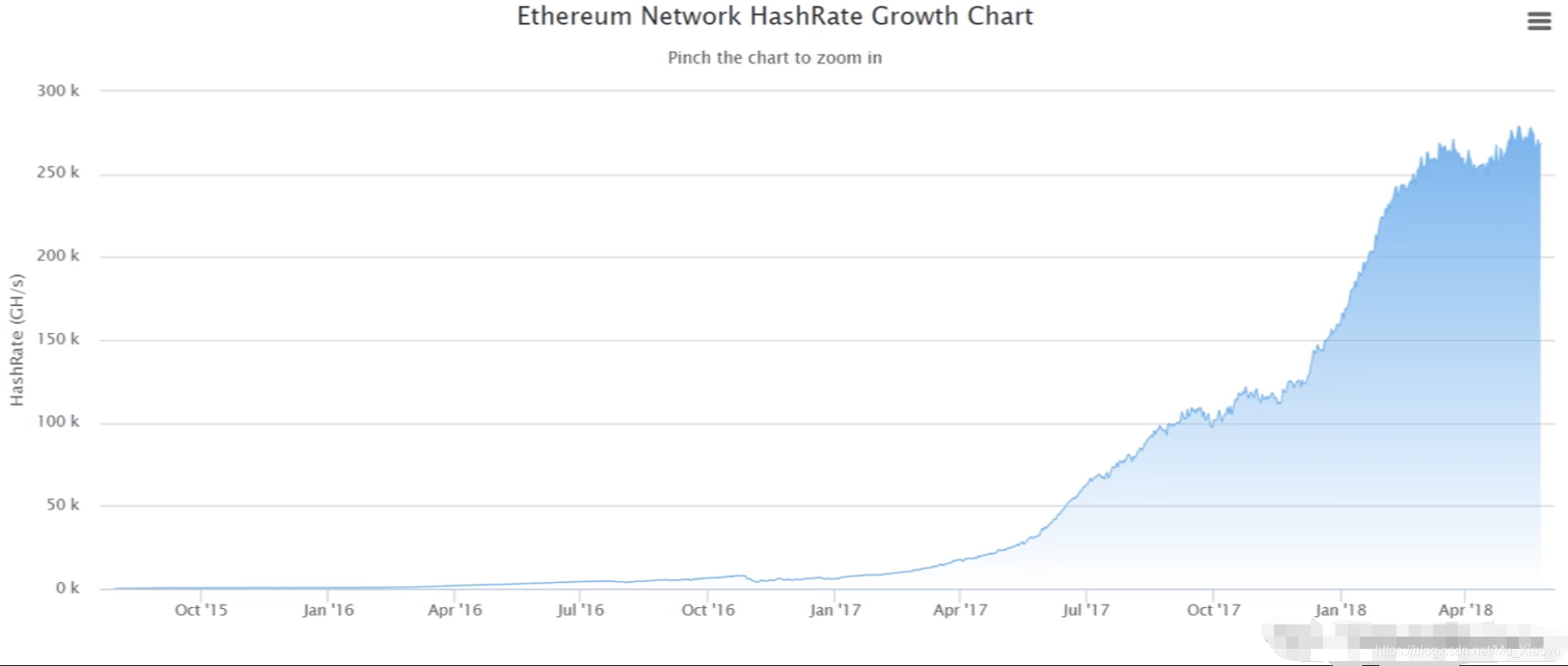
这指的是所有矿工每秒加起来的Hashis的数量。 如果不同的编码货币使用不同,他们的散列率无法比较,在Taiku和Bitcoin则无法比较。
本节的采矿算法设计倾向于让公众参与,这是公平的,参与者的分散和他们的算术的分散使这个系统更加安全。
但也有一些人认为,像Bitcoin那样在采矿中使用通用计算机不安全,在采矿中使用集中池塘也是安全的。 为什么呢?
如果一个系统要受到攻击,许多只能制造特定货币矿的矿工必须进行51%的武力对武力攻击。 袭击成功后,这不可避免地会导致货币价值下降,袭击者投入的硬件成本也将损失。 如果通用计算机也参与采矿,发动袭击的成本将大幅降低,而目前的大型互联网公司将有能力收集服务器并袭击这些服务器,而一旦完成,这些服务器仍将变成日常业务。
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群












发表评论