
虚拟数字人:元宇宙的主角破圈而来 虚拟人、数字人、虚拟数字人的目标是通过 计算机 图形学技术(Computer Graphic,CG)创造出与人类形象接近...
资讯 2024-07-03 阅读:176 评论:0


虚拟人、数字人、虚拟数字人的目标是通过计算机图形学技术(Computer Graphic,CG)创造出与人类形象接近的数字化形象,并赋予其特定的人物身份设定,在视觉上拉近和人的心理距离,为人类带来更加真实的情感互动。按照各定义特征的要求,数字人的范畴包含虚拟人,虚拟人的范畴包含虚拟数字人。
The objective of the virtual person, digital person, virtual digital person is to create a digital image close to the image of the human person and to give it a specific character identity set, which brings a more real emotional interaction to the human person by visual proximity and psychological distance . As required by the defining characteristics, the sphere of the digital person includes the virtual person and the virtual digital person.
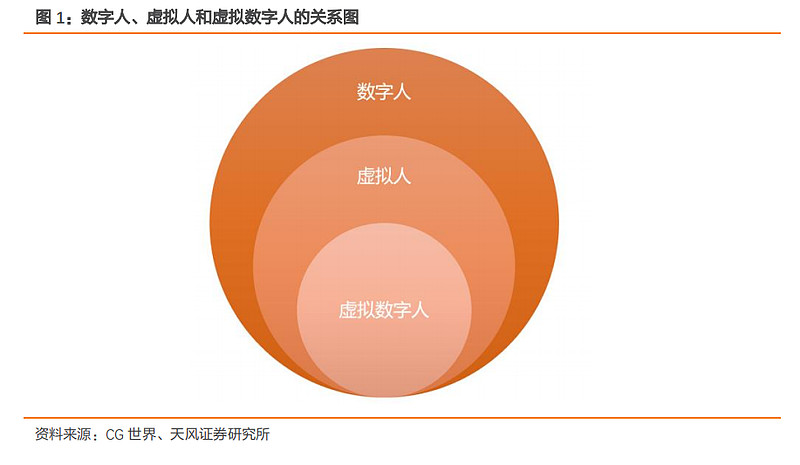
对于不要求必须具备交流互动能力时,数字人、虚拟人、虚拟数字人这三者概念可以认为是等同的。但在严格意义下它们又有细微的差别。虚拟人的身份是虚构的,现实世界中不存在的。数字人强调角色存在于数字世界。虚拟数字人强调虚拟身份和数字化制作特性。
The concepts of digitals, virtuals, and virtual digitals can be considered to be equivalents if the ability to interact is not required. but they differ slightly in the strict sense. Virtual identities are fictional, non-existent in the real world. Digital figures stress the role in the digital world. Virtual digital figures emphasize virtual identities and digital production.

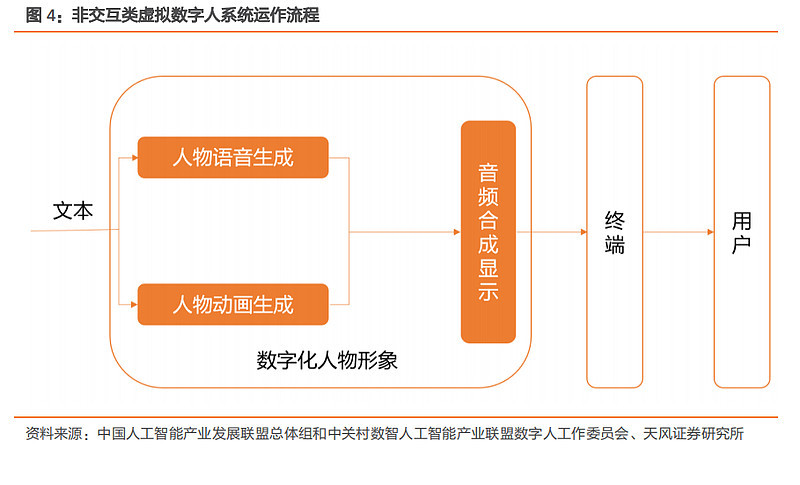
人物形象根据人物图形资源的维度,可分为 2D 和 3D 两大类;语音和动画生成模块可分别基于文本生成对应的人物语音以及人物动画;音视频合成显示模块将语音和动画合成视频;交互模块根据语音语义识别用户的意图,并决定数字人后续的语音和动作。
Personal images can be divided into two broad categories of according to the dimensions of the graphic resources of a person; voice and animation generation modules can generate the corresponding voice of a person and animation of a person on the basis of text, respectively; audio and video synthesis modules synthesize the voice and animated video; interactive modules identify the intent of the user according to the tone of the voice and determine the subsequent voice and movement of the digital person.
来源行行查数据库:网页链接
下载更多完整报告 请访问:网页链接
Source line search database: 智能驱动型数字人可通过智能系统自动读取并解析识别外界输入信息,根据解析结果决策数字人后续的输出文本,然后驱动人物模型生成相应的语音与动作来使数字人跟用户互动。该人物模型是预先通过 AI 技术训练得到的,可通过文本驱动生成语音和对应动画,业内将此模型称为 TTSA(Text To Speech & Animation)人物模型。 Smart-driven digitals can automatically read and interpret external input information through an intelligent system, decides the output text that follows a digital person on the basis of the parsing results, and then the driver model produces the corresponding voice and action to interact with the digital person. The character model is pre-trained by AI technology and can generate voice and resonance animations through text-driven text-driven models called TTSA (Text To Speech & Animation) character models. 真人驱动型数字人则是通过真人来驱动数字人,主要原理是真人根据视频监控系统传来的用户视频,与用户实时语音,同时通过动作捕捉采集系统将真人的表情、动作呈现在虚拟数字人形象上,从而与用户进行交互。 The real-person-driven digital person drives the digital person through the real person, and is primarily based on the real-time voice of the user based on the video surveillance system, while at the same time interacting with the user by acting to capture the face and actions of the real person on the virtual digital person image.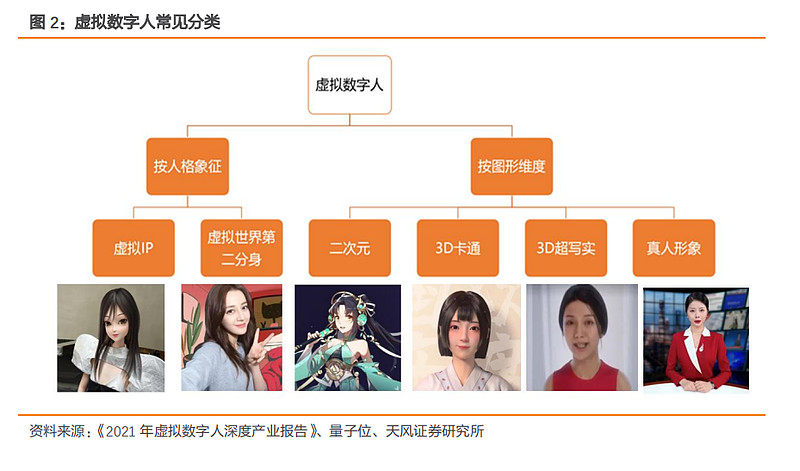

注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群












发表评论